
By Hendrik Strobelt and Sebastian Gehrmann -- reviewed by Alexander Rush
A collaboration of MIT-IBM Watson AI
lab
and HarvardNLP
We introduce GLTR to inspect the visual footprint of automatically generated tex. It enables a forensic analysis of how likely an automatic system has generated a text.
Find the SOURCE CODE on Github
Read the ACL 2019 demo track paper (nominated for best demo)
In recent years, the natural language processing community has seen the development of increasingly larger and larger language models.
A language model is a machine learning model that is trained to predict the next word given an input context. As such, a model can generate text by generating one word at a time. These predictions can even, to some extent, be constrained by human-provided input to control what the model writes about. Due to their modeling power, large language models have the potential to generate textual output that is indistinguishable from human-written text to a non-expert reader.
Language models achieve this with incredibly accurate distributional estimates of what words may follow in a given context. If a generation system uses a language model and predicts a very likely next words, the generation will look similar to what word a human would have picked in similar situation, despite not having much knowledge about the context itself. This opens up paths for malicious actors to use these tools to generate fake reviews, comments or news articles to influence the public opinion.
To prevent this from happening, we need to develop forensic techniques to detect automatically generated text. We make the assumption that computer generated text fools humans by sticking to the most likely words at each position, a trick that fools humans. In contrast, natural writing actually more frequently selects unpredictable words that make sense to the domain. That means that we can detect whether a text actually looks too likely to be from a human writer!
GLTR represents a visually forensic tool to detect text that was automatically generated from large language models.
The aim of GLTR is to take the same models that are used to generated fake text as a tool for detection. GLTR has access to the GPT-2 117M language model from OpenAI, one of the largest publicly available models. It can use any textual input and analyze what GPT-2 would have predicted at each position. Since the output is a ranking of all of the words that the model knows, we can compute how the observed following word ranks. We use this positional information to overlay a colored mask over the text that corresponds to the position in the ranking. A word that ranks within the most likely words is highlighted in green (top 10), yellow (top 100), red (top 1,000), and the rest of the words in purple. Thus, we can get a direct visual indication of how likely each word was under the model.

While it is possible to paste any text into the tool, we provided some examples of fake and real texts. Notice that the fraction of red and purple words, i.e. unlikely predictions, increases when you move to the real texts. Moreover, we found that the informative snippets within a text almost always appear in red or purple since these "surprising" terms carry the message of the text.

By hovering over a word in the display, a small box presents the top 5 predicted words, their associated probabilities, as well as the position of the following word. It is a fun exercise to look into what a model would have predicted.

Finally, the tool shows three different histograms that aggregate the information over the whole text. The first one demonstrates how many words of each category appear in the text. The second one illustrates the ratio between the probabilities of the top predicted word and the following word. The last histogram shows the distribution over the entropies of the predictions. A low uncertainty implies that the model was very confident of each prediction, whereas a high uncertainty implies uncertainty. You can observe that for the academic text input, the uncertainty is generally higher than the samples from the model.
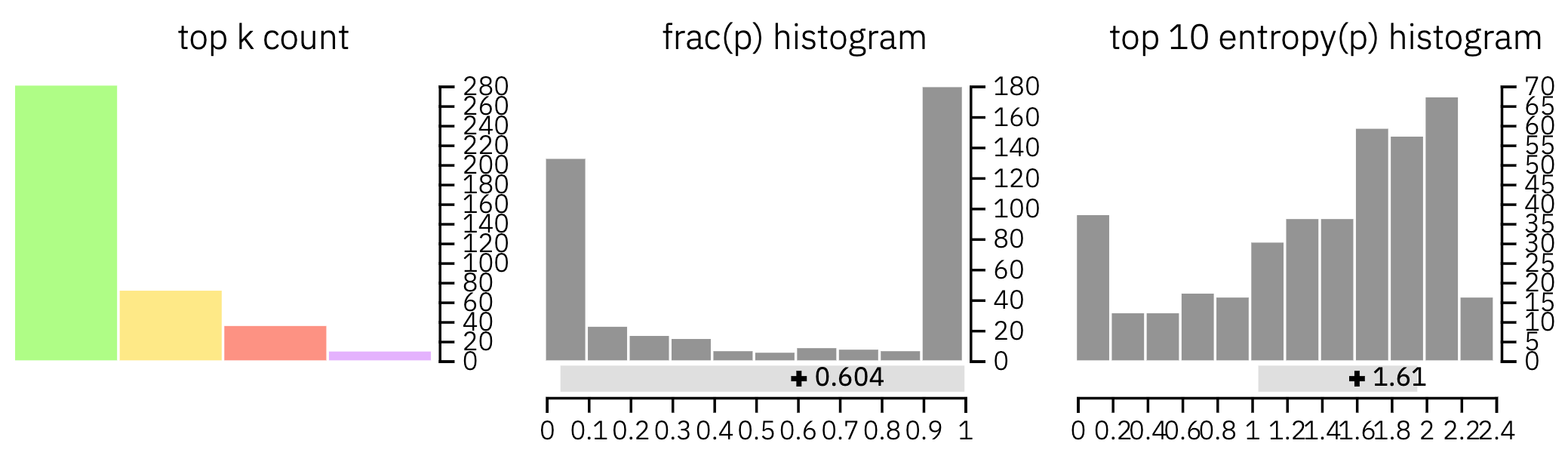
As a first example, we investigate a now famous generated text, the unicorn sample from an unreleased GPT-2 model developed by OpenAI. The first sentence is the prompt given to the model, and the rest of the text is entirely generated. The text looks very realistic and it is very hard to detect from reading it whether it was written by an algorithm or a human.

We can see that there is not a single purple word and only a few red words throughout the text. Most words are green or yellow, which is a strong indicator that this is a generated text.
Looking at the histograms, we can see additional hints at the automatic generation. There is a strong indication that the model generally assigned a high probability to the correct word. Moreover, the uncertainty is often very low, which indicates an overall low level of surprise for the model. Note that we can detect that the text is artificial even without access to the real model, since we use a smaller version of the model that actually generated this text. Access to the real underlying model would likely strengthen the detected signal.
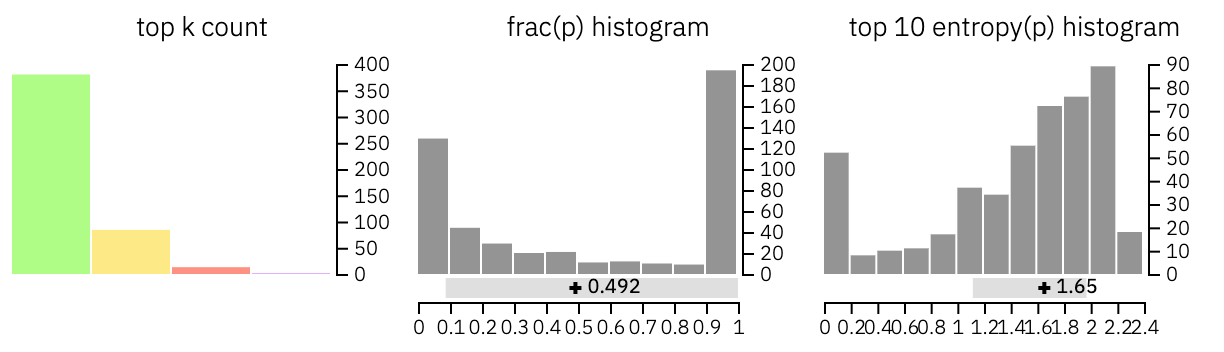
We begin the analysis of real text with an example text from the GRE, copied from here. The GRE tests are reading comprehension at a reasonably high level and we thus expect a higher percentage of more complex and unexpected words.
Upon visual inspection, we can observe many unexpected purple and red words and very high uncertainty. These observations are strong indicators of a human-written text.
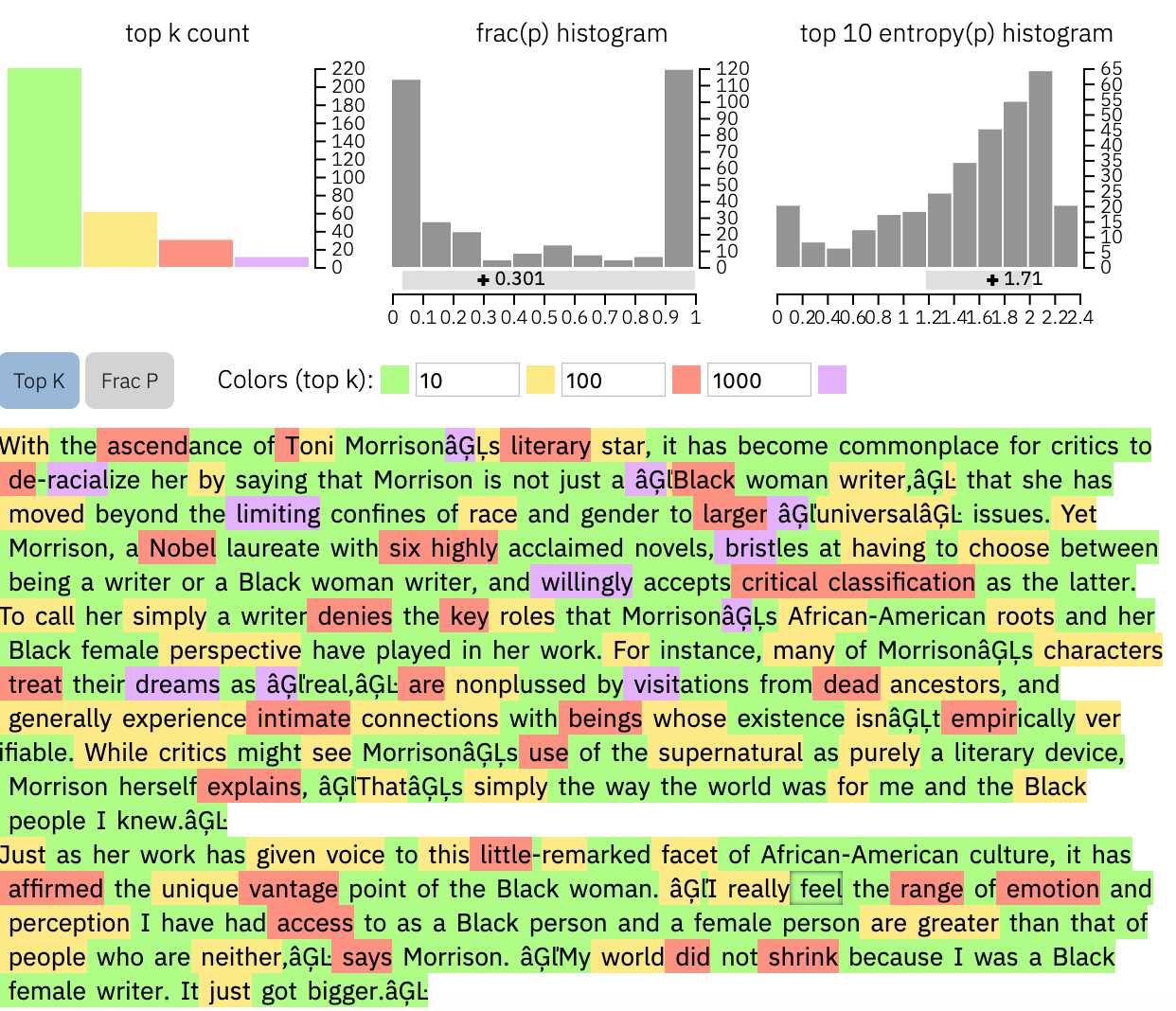
We next show GLTR a scientific abstract, taken from this paper about predicting CRISPR-outcomes, published in nature.
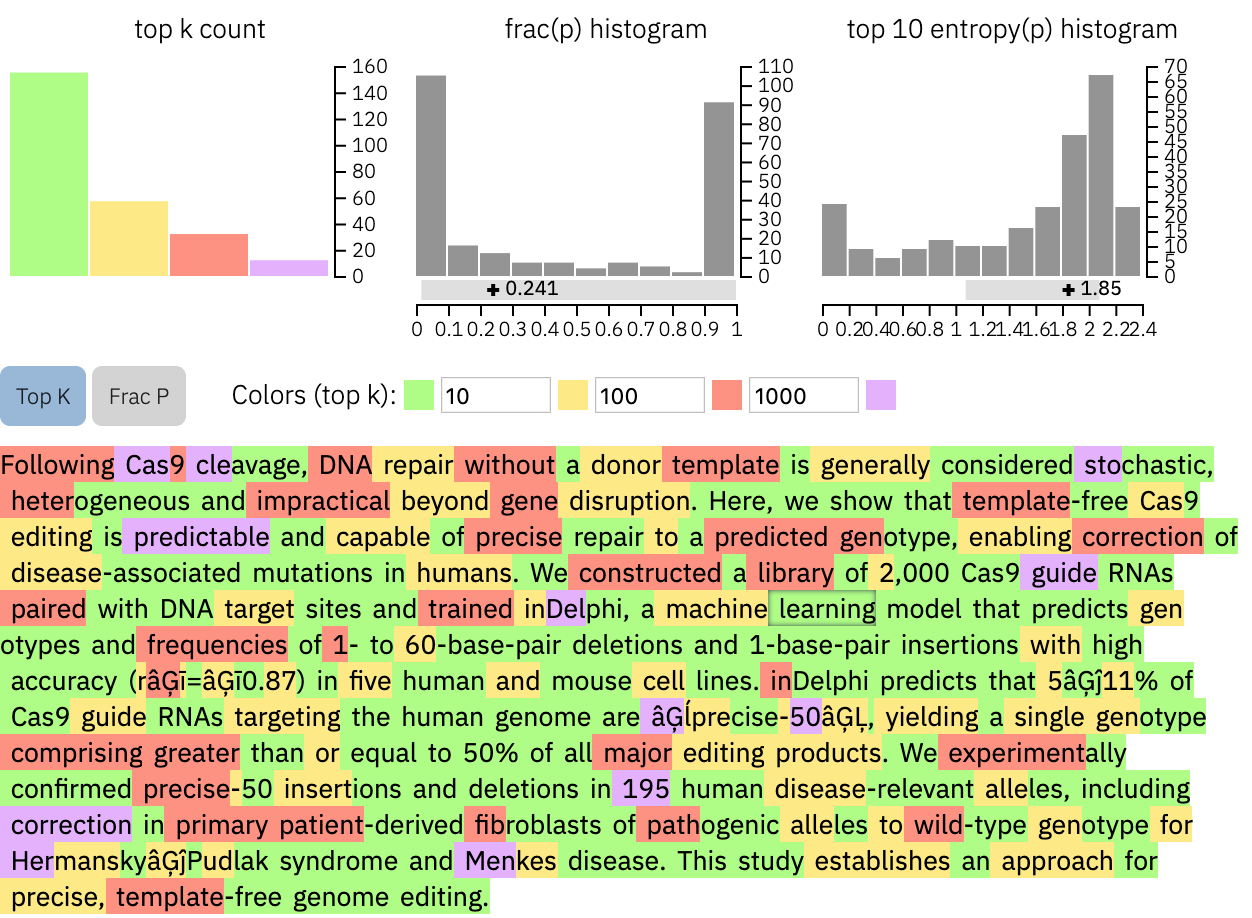
The tool shows a remarkably high fraction of red and purple words, which suggests that this is a human-written text. Moreover, the uncertainty histogram is very right-skewed, yet another indicator. Upon consultation with the first author of this work, we confirmed that this abstract was in fact written by a human.
We can use this tool to analysize other automatic text generation systems. For isntance,
The Washington Post utilizes algorithms to report on sporting events and elections (see here). Below, we show the GLTR output when showing it one such article.

Remarkably, almost everything but the named entities (players and teams) is green and yellow. Even though we do not have access to the underlying model, the visual footprint looks as if this article was written autonomously or semi-autonomously by the algorithm.
We used the GPT-2 model itself to produce non-conditioned text by sampling from the top 40 predictions. The image below shows the clear picture that the model can detect its own text pretty well (all green and yellow):

Now it is onto you. What other effects can you detect with our tool?
Find us on twitter as @hen_str, @sebgehr, and @harvardnlp and let us know! Email: info@gltr.io
@inproceedings{gehrmann-etal-2019-gltr,
title = "{GLTR}: Statistical Detection and Visualization of Generated Text",
author = "Gehrmann, Sebastian and
Strobelt, Hendrik and
Rush, Alexander",
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations",
month = jul,
year = "2019",
address = "Florence, Italy",
publisher = "Association for Computational Linguistics",
doi = "10.18653/v1/P19-3019",
pages = "111--116",
abstract = "The rapid improvement of language models has raised the specter of abuse of text generation systems. This progress motivates the development of simple methods for detecting generated text that can be used by non-experts. In this work, we introduce GLTR, a tool to support humans in detecting whether a text was generated by a model. GLTR applies a suite of baseline statistical methods that can detect generation artifacts across multiple sampling schemes. In a human-subjects study, we show that the annotation scheme provided by GLTR improves the human detection-rate of fake text from 54{\%} to 72{\%} without any prior training. GLTR is open-source and publicly deployed, and has already been widely used to detect generated outputs.",
}
Obviously, GLTR is not perfect. Its main limitation is its limited scale. It won't be able to automatically detect large-scale abuse, only individual cases. Moreover, it requires at least an advanced knowledge of the language to know whether an uncommon word does make sense at a position. Our assumption is also limited in that it assumes a simple sampling scheme. Adversaries might change the sampling parameters per word or sentence to make it look more similar to the language it is trying to imitate. However, we speculate that an adversarial sampling scheme would lead to worse text, as the model would be forced to generate words it deemed unlikely. This would lead to other detectable properties in a text. Therefore, despite its limitations, we believe that GLTR can spark the development of similar ideas that work at greater scale.
We are grateful to Ken Arnold, David Bau, David Cox, Barbara Grosz, Robert Krüger, Steve Ross, and Yonatan Belinkov for trying out GLTR, finding examples and discussing the tool. We finally thank Thomas Wolf and HuggingFace for the Pytorch ports of the model we use.